Visão Geral da Tecnologia Hadoop

Hadoop é um framework de software de código aberto criado pela Apache Software Foundation. Ele é projetado para permitir o processamento e armazenamento de grandes volumes de dados em um ambiente distribuído, usando hardware comum. A arquitetura modular e escalável do Hadoop o torna ideal para trabalhar com Big Data, permitindo que empresas coletem, armazenem, processem e analisem dados de forma eficiente.
Componentes Principais do Hadoop
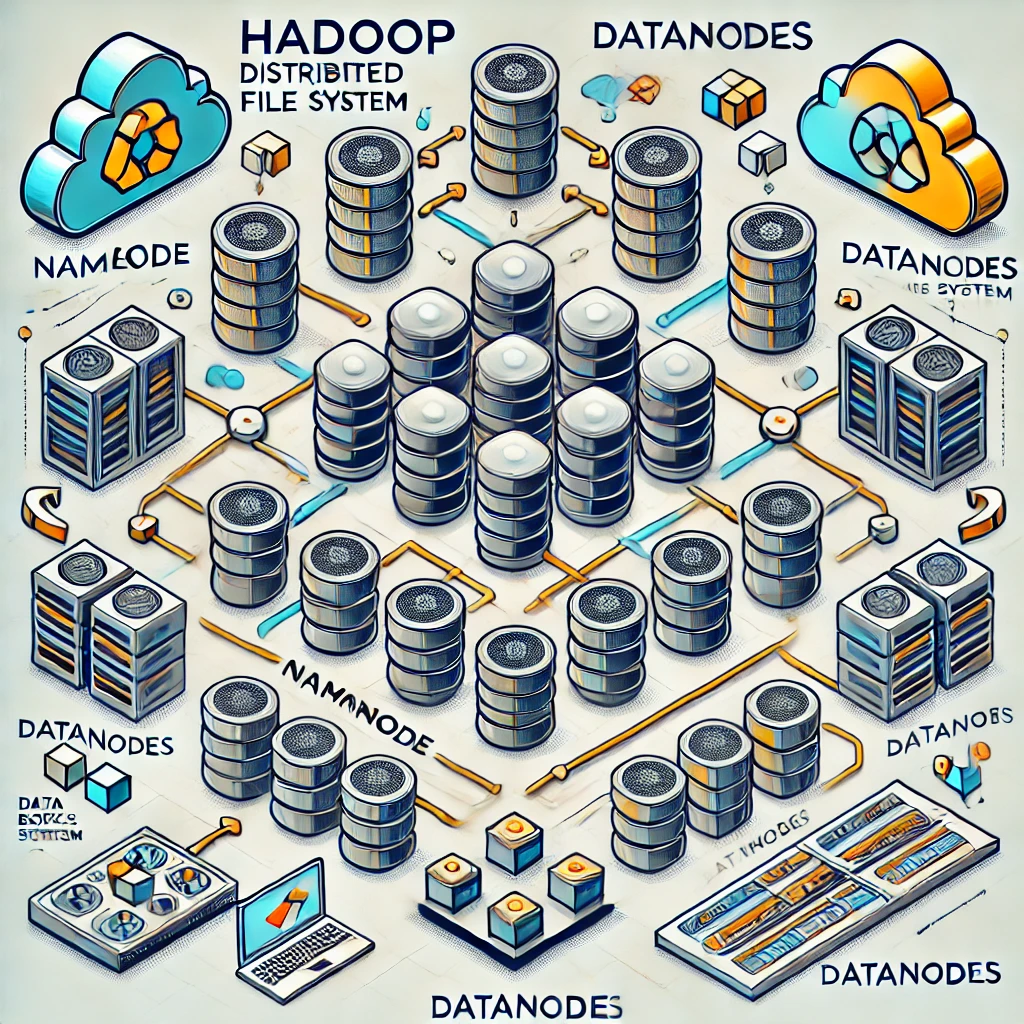
- Hadoop Distributed File System (HDFS):
- O que é: HDFS é o sistema de arquivos distribuído que armazena dados em blocos e distribui esses blocos entre vários nós no cluster, garantindo alta disponibilidade e tolerância a falhas.
- Como Funciona: Os dados são divididos em blocos (tipicamente de 128 MB ou 256 MB) e replicados em vários nós (por padrão, três cópias) para garantir a durabilidade e a resiliência a falhas de hardware.
- Vantagens: Escalabilidade horizontal, alta tolerância a falhas, e capacidade de lidar com grandes volumes de dados.
- YARN (Yet Another Resource Negotiator):
- O que é: YARN é o sistema de gerenciamento de recursos do Hadoop, que coordena a alocação de recursos (CPU, memória) e a execução de aplicações em um cluster.
- Como Funciona: Ele gerencia as solicitações de recursos feitas pelos aplicativos e distribui a carga de trabalho, permitindo que múltiplos frameworks (como MapReduce, Spark, e outros) possam rodar no mesmo cluster.
- Vantagens: Otimização no uso de recursos do cluster, suporte a múltiplos frameworks de processamento de dados, e melhor utilização da infraestrutura.
- MapReduce:
- O que é: MapReduce é o modelo de programação do Hadoop para processamento paralelo de grandes conjuntos de dados. Ele divide as tarefas em duas etapas principais: Map (mapeamento) e Reduce (redução).
- Como Funciona: A fase Map processa os dados de entrada e gera pares chave-valor, enquanto a fase Reduce combina esses pares em resultados finais. Essa abordagem permite a execução distribuída e paralela das tarefas.
- Vantagens: Alta escalabilidade e eficiência no processamento paralelo, ideal para operações que envolvem grandes volumes de dados, como filtragem, agregação, e análise.
- Hadoop Common:
- O que é: Hadoop Common é um conjunto de utilitários e bibliotecas essenciais que suportam os outros módulos do Hadoop, fornecendo funcionalidades como I/O, compressão, e segurança.
- Como Funciona: Ele atua como uma base que conecta e integra os diferentes componentes do Hadoop, permitindo uma comunicação coesa e eficiente entre eles.
Características e Vantagens do Hadoop
- Escalabilidade:
- O Hadoop pode escalar horizontalmente, ou seja, você pode adicionar mais nós ao cluster sem necessidade de reconfigurações significativas, aumentando a capacidade de armazenamento e processamento conforme necessário.
- Alta Tolerância a Falhas:
- Com a replicação de dados no HDFS, o Hadoop consegue continuar operando mesmo se um ou mais nós falharem. O sistema detecta automaticamente falhas e redireciona as tarefas para outros nós.
- Custo-Efetividade:
- O Hadoop é projetado para rodar em hardware comum, o que significa que você não precisa investir em servidores caros para gerenciar grandes volumes de dados.
- Flexibilidade no Tipo de Dados:
- Diferentemente dos sistemas de banco de dados tradicionais que exigem dados estruturados, o Hadoop pode processar dados estruturados, semiestruturados, e não estruturados (como logs de servidores, textos, imagens, e vídeos).
- Ecosistema Amplo:
- Hadoop possui um ecossistema rico que inclui ferramentas como Apache Hive (para consulta de dados usando SQL), Apache Pig (para processamento de dados de alto nível), Apache HBase (para armazenamento de dados em tempo real), Apache Spark (para processamento de dados em memória), entre outras.
Casos de Uso Comuns do Hadoop
- Análise de Big Data:
- Empresas usam Hadoop para analisar grandes volumes de dados para extrair insights, otimizar operações, e tomar decisões baseadas em dados.
- Armazenamento e Backup de Dados:
- HDFS é frequentemente utilizado como um repositório de dados centralizado, onde grandes quantidades de dados são armazenadas e podem ser acessadas para processamento ou arquivamento.
- Machine Learning e Inteligência Artificial:
- Hadoop serve como base para grandes conjuntos de dados usados no treinamento de modelos de Machine Learning e IA, oferecendo capacidade de processamento distribuído.
- Processamento de Dados em Tempo Real:
- Com a integração de ferramentas como Apache Kafka e Apache Flink, Hadoop pode ser usado para processar fluxos de dados em tempo real, útil em aplicações como detecção de fraudes e análise de comportamento do cliente.
Desafios do Hadoop
- Curva de Aprendizado:
- Configurar e gerenciar um cluster Hadoop requer conhecimentos técnicos avançados em Linux, Java, redes, e gerenciamento de recursos.
- Gerenciamento de Recursos:
- A configuração inadequada do YARN e HDFS pode levar a problemas de desempenho, como gargalos de I/O e uso ineficiente de CPU e memória.
- Segurança e Governança de Dados:
- Embora o Hadoop ofereça mecanismos de segurança como autenticação Kerberos e encriptação, configurar essas medidas pode ser complexo e demanda atenção para garantir a proteção dos dados.
- Manutenção do Cluster:
- Manter um cluster Hadoop requer monitoramento constante e ajuste fino para evitar falhas e garantir que os recursos sejam utilizados de maneira otimizada.
Conclusão
Hadoop é uma solução poderosa para o processamento de Big Data, com capacidade para lidar com grandes volumes de dados de maneira eficiente e econômica. A flexibilidade de seu ecossistema e a capacidade de escalabilidade tornam o Hadoop uma escolha popular em várias indústrias, desde tecnologia e finanças até saúde e telecomunicações. No entanto, a implementação bem-sucedida exige um entendimento sólido de suas capacidades e limitações, além de uma gestão cuidadosa do ambiente.

Leave a comment