
Capítulo 2: Conceitos Fundamentais
2.1. População e Amostra
População
A população refere-se ao conjunto completo de todos os elementos ou indivíduos que estão sendo estudados. Pode ser um grupo de pessoas, objetos ou eventos que possuem características em comum. Em estatística, uma população é frequentemente muito grande para ser medida na íntegra, o que torna a coleta de dados para toda a população impraticável.
Exemplo: Se estamos estudando a altura de todos os alunos em uma escola, a população é composta por todos os alunos dessa escola.
Amostra
Uma amostra é um subconjunto da população que é selecionado para representar o grupo maior. A seleção da amostra deve ser feita de maneira que ela seja representativa da população para garantir que os resultados da análise sejam válidos e generalizáveis.
Exemplo: Se medirmos a altura de 50 alunos selecionados aleatoriamente da escola, esses 50 alunos formam a amostra.
Diferenças e Exemplos
- População: Todos os clientes de uma empresa.
- Amostra: 100 clientes selecionados aleatoriamente para uma pesquisa de satisfação.
A seleção adequada da amostra e a compreensão das diferenças entre população e amostra são essenciais para a realização de análises estatísticas precisas.
2.2. Medidas de Tendência Central
As medidas de tendência central ajudam a descrever o valor típico ou central em um conjunto de dados. As principais medidas são:
Média
A média é a soma de todos os valores dividida pelo número total de valores. É uma medida comum de tendência central.
Fórmula:
[ \text{Média} = \frac{\sum x_i}{n} ]
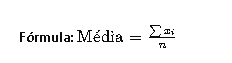
Exemplo com Python:
import numpy as np
data = [10, 20, 20, 40, 50, 60, 70, 80, 90, 100]
mean = np.mean(data)
print(f"Média: {mean}")
Mediana
A mediana é o valor que separa os dados em duas partes iguais quando os dados estão ordenados. Se houver um número ímpar de observações, a mediana é o valor central. Se houver um número par, é a média dos dois valores centrais.
Exemplo com Python:
import numpy as np
data = [10, 20, 20, 40, 50, 60, 70, 80, 90, 100]
median = np.median(data)
print(f"Mediana: {median}")
Moda
A moda é o valor que aparece com maior frequência em um conjunto de dados. Um conjunto de dados pode ter uma única moda, mais de uma moda ou nenhuma moda.
Exemplo com Python:
import pandas as pd
data = [10, 20, 20, 40, 50, 60, 70, 80, 90, 100]
mode = pd.Series(data).mode()[0]
print(f"Moda: {mode}")
2.3. Medidas de Dispersão
As medidas de dispersão fornecem informações sobre a variabilidade dos dados. Elas ajudam a entender o quanto os dados estão espalhados em torno da média.
Desvio Padrão
O desvio padrão mede a quantidade de variação ou dispersão em um conjunto de dados. Quanto menor o desvio padrão, mais próximos os dados estão da média.
Fórmula:
[ \text{Desvio Padrão} = \sqrt{\frac{\sum (x_i – \bar{x})^2}{n}} ]

Exemplo com Python:
import numpy as np
data = [10, 20, 20, 40, 50, 60, 70, 80, 90, 100]
std_dev = np.std(data)
print(f"Desvio Padrão: {std_dev}")
Variância
A variância é o quadrado do desvio padrão e também mede a dispersão dos dados.
Fórmula:
[ \text{Variância} = \frac{\sum (x_i – \bar{x})^2}{n} ]
Exemplo com Python:
import numpy as np
data = [10, 20, 20, 40, 50, 60, 70, 80, 90, 100]
variance = np.var(data)
print(f"Variância: {variance}")
Intervalo
O intervalo é a diferença entre o maior e o menor valor em um conjunto de dados. Ele fornece uma visão geral da amplitude dos dados.
Exemplo com Python:
data = [10, 20, 20, 40, 50, 60, 70, 80, 90, 100]
range_val = np.ptp(data)
print(f"Intervalo: {range_val}")
Este capítulo aborda os conceitos fundamentais de população, amostra e medidas de tendência central e dispersão, fornecendo uma base sólida para análises estatísticas mais avançadas. Nos próximos capítulos, exploraremos conceitos adicionais de probabilidade e inferência estatística, sempre utilizando exemplos práticos em Python para facilitar a compreensão.
Este livro é o resultado de uma colaboração cuidadosa entre o autor e um assistente virtual especializado em tecnologia e programação. A ideia inicial e a concepção do conteúdo foram desenvolvidas pelo autor, que buscou criar um recurso acessível e prático para quem deseja aprender os fundamentos da estatística utilizando Python.
A execução e organização do conteúdo, incluindo os exemplos de código e as explicações técnicas, foram elaboradas com o auxílio do assistente virtual. Juntos, trabalhamos para garantir que cada conceito fosse apresentado de forma clara e que os exemplos de código fossem relevantes e fáceis de entender.
Agradecemos ao leitor por acompanhar este trabalho. Esperamos que este livro sirva como uma base sólida para sua jornada no mundo da estatística e que os exemplos práticos com Python sejam úteis e esclarecedores. Se você tiver dúvidas ou sugestões, ficaremos felizes em receber seu feedback.

Leave a comment